ADARO-RL Pipelines Example
Imports
[1]:
import os
import sys
import shutil
from pathlib import Path
import adaro_rl
import adaro_rl.viz
import adaro_rl.zoo as zoo
/home/jovyan/Maturation/env-adaro-rl/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Arguments
[2]:
config_name="Enduro-v5"
attack_name="FGM_D"
target="untargeted"
eps=100.0
norm=2.0
training_steps=2000
n_eval_episodes=2
device="cuda"
seed=0
Ouputs Directory
[3]:
output_dir = os.path.join("outputs", f"{config_name}", f"attack_{attack_name}_target_{target}_eps_{eps}_norm_{norm}")
agent_dir = os.path.join(output_dir,"agent")
adv_trained_dir = os.path.join(output_dir,"adv_trained_agent")
output_path = Path(output_dir)
agent_path = Path(agent_dir)
# Create the directory using the Path object
output_path.mkdir(parents=True, exist_ok=True)
Define Config
[4]:
config = zoo.configs[config_name]
Download the model
[5]:
print("📥 Download the agent")
agent_path.mkdir(parents=True, exist_ok=True)
if not os.path.isfile(os.path.join(agent_dir,"model.zip")):
zoo.download_model(config_name, local_dir=str(agent_dir))
else:
print(f"{os.path.join(agent_dir,'model.zip')} already exists")
📥 Download the agent
outputs/Enduro-v5/attack_FGM_D_target_untargeted_eps_100.0_norm_2.0/agent/model.zip already exists
Train the Agent
[6]:
print("\n🏋️ Train the agent")
adaro_rl.train(
config=config,
checkpoint=os.path.join(agent_dir,"model.zip"),
output_dir=str(agent_dir),
device=device,
seed=seed,
total_timesteps=training_steps,
prepopulate_timesteps=0,
verbose=False
)
🏋️ Train the agent
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
/home/jovyan/Maturation/env-adaro-rl/lib/python3.10/site-packages/rich/live.py:231: UserWarning: install
"ipywidgets" for Jupyter support
warnings.warn('install "ipywidgets" for Jupyter support')
/home/jovyan/Maturation/env-adaro-rl/lib/python3.10/site-packages/stable_baselines3/common/on_policy_algorithm.py:150: UserWarning: You are trying to run PPO on the GPU, but it is primarily intended to run on the CPU when not using a CNN policy (you are using ActorCriticPolicy which should be a MlpPolicy). See https://github.com/DLR-RM/stable-baselines3/issues/1245 for more info. You can pass `device='cpu'` or `export CUDA_VISIBLE_DEVICES=` to force using the CPU.Note: The model will train, but the GPU utilization will be poor and the training might take longer than on CPU.
warnings.warn(
Evaluate the Agent
[7]:
print("\n🧪 Test the agent")
adaro_rl.pipelines.test(
config=config,
checkpoint=os.path.join(agent_dir,"model.zip"),
output_dir=os.path.join(agent_dir,"results"),
device=device,
seed=seed,
n_eval_episodes=n_eval_episodes
)
🧪 Test the agent
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
lengths : [6656, 6656]
mean : 6656.0
std : 0.0
rewards : [483.0, 496.0]
mean : 489.5
std : 6.5
Evaluate the Agent against the Attack
[8]:
print(f"\n🧨 Online attack: {attack_name}_{target}_{eps}_{norm}")
adaro_rl.pipelines.online_attack(
config=config,
attack_name=attack_name,
target=target,
eps=eps,
norm=norm,
output_dir=os.path.join(agent_dir,"results"),
agent_checkpoint=os.path.join(agent_dir,"model.zip"),
adversary_checkpoint=None,
self_reference=True,
device=device,
seed=seed,
n_eval_episodes=n_eval_episodes
)
🧨 Online attack: FGM_D_untargeted_100.0_2.0
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
/home/jovyan/Maturation/env-adaro-rl/lib/python3.10/site-packages/stable_baselines3/common/on_policy_algorithm.py:150: UserWarning: You are trying to run PPO on the GPU, but it is primarily intended to run on the CPU when not using a CNN policy (you are using ActorCriticPolicy which should be a MlpPolicy). See https://github.com/DLR-RM/stable-baselines3/issues/1245 for more info. You can pass `device='cpu'` or `export CUDA_VISIBLE_DEVICES=` to force using the CPU.Note: The model will train, but the GPU utilization will be poor and the training might take longer than on CPU.
warnings.warn(
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
lengths : [3328, 6656]
mean : 4992.0
std : 1664.0
rewards : [157.0, 475.0]
mean : 316.0
std : 159.0
save in outputs/Enduro-v5/attack_FGM_D_target_untargeted_eps_100.0_norm_2.0/agent/results/online_adv_attacks_norm_2.0_mean_reward.csv and outputs/Enduro-v5/attack_FGM_D_target_untargeted_eps_100.0_norm_2.0/agent/results/online_adv_attacks_norm_2.0_std_reward.csv
Advesarial Training of the Agent aginst the Attack
[9]:
print(f"\n🛡️ Adversarial training: {attack_name}_{target}_{eps}_{norm}")
adaro_rl.pipelines.adversarial_train(
config=config,
attack_name=attack_name,
target=target,
eps=eps,
norm=norm,
output_dir=str(adv_trained_dir),
agent_checkpoint=os.path.join(agent_dir,"model.zip"),
adversary_checkpoint=None,
self_reference=True,
device=device,
seed=seed,
total_timesteps=training_steps,
prepopulate_timesteps=0,
verbose=False
)
🛡️ Adversarial training: FGM_D_untargeted_100.0_2.0
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
/home/jovyan/Maturation/env-adaro-rl/lib/python3.10/site-packages/stable_baselines3/common/on_policy_algorithm.py:150: UserWarning: You are trying to run PPO on the GPU, but it is primarily intended to run on the CPU when not using a CNN policy (you are using ActorCriticPolicy which should be a MlpPolicy). See https://github.com/DLR-RM/stable-baselines3/issues/1245 for more info. You can pass `device='cpu'` or `export CUDA_VISIBLE_DEVICES=` to force using the CPU.Note: The model will train, but the GPU utilization will be poor and the training might take longer than on CPU.
warnings.warn(
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
/home/jovyan/Maturation/env-adaro-rl/lib/python3.10/site-packages/rich/live.py:231: UserWarning: install
"ipywidgets" for Jupyter support
warnings.warn('install "ipywidgets" for Jupyter support')
Evaluate the Adversarially Trained Agent
[10]:
print("\n🔬 Test the adversarially trained agent")
adaro_rl.pipelines.test(
config=config,
checkpoint=os.path.join(adv_trained_dir,"model.zip"),
output_dir=os.path.join(adv_trained_dir,"results"),
device=device,
seed=seed,
n_eval_episodes=n_eval_episodes
)
🔬 Test the adversarially trained agent
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
lengths : [6656, 9984]
mean : 8320.0
std : 1664.0
rewards : [487.0, 682.0]
mean : 584.5
std : 97.5
Evaluate the Adversarially Trained Agent, against the Attack
[11]:
print(f"\n🧨 Online attack on adversarially trained agent: {attack_name}_{target}_{eps}_{norm}")
adaro_rl.pipelines.online_attack(
config=config,
attack_name=attack_name,
target=target,
eps=eps,
norm=norm,
output_dir=os.path.join(adv_trained_dir,"results"),
agent_checkpoint=os.path.join(adv_trained_dir,"model.zip"),
adversary_checkpoint=None,
self_reference=True,
device=device,
seed=seed,
n_eval_episodes=n_eval_episodes
)
🧨 Online attack on adversarially trained agent: FGM_D_untargeted_100.0_2.0
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
/home/jovyan/Maturation/env-adaro-rl/lib/python3.10/site-packages/stable_baselines3/common/on_policy_algorithm.py:150: UserWarning: You are trying to run PPO on the GPU, but it is primarily intended to run on the CPU when not using a CNN policy (you are using ActorCriticPolicy which should be a MlpPolicy). See https://github.com/DLR-RM/stable-baselines3/issues/1245 for more info. You can pass `device='cpu'` or `export CUDA_VISIBLE_DEVICES=` to force using the CPU.Note: The model will train, but the GPU utilization will be poor and the training might take longer than on CPU.
warnings.warn(
A.L.E: Arcade Learning Environment (version 0.10.1+unknown)
[Powered by Stella]
lengths : [6656, 6656]
mean : 6656.0
std : 0.0
rewards : [393.0, 434.0]
mean : 413.5
std : 20.5
save in outputs/Enduro-v5/attack_FGM_D_target_untargeted_eps_100.0_norm_2.0/adv_trained_agent/results/online_adv_attacks_norm_2.0_mean_reward.csv and outputs/Enduro-v5/attack_FGM_D_target_untargeted_eps_100.0_norm_2.0/adv_trained_agent/results/online_adv_attacks_norm_2.0_std_reward.csv
[12]:
attack_name = attack_name + "_" + target
fig = adaro_rl.viz.robustness_matrix(
env_name=config_name,
agent_dirs=[agent_dir, adv_trained_dir],
agent_names=["agent", "adv_trained_agent"],
norm=norm,
attack_list=[attack_name],
eps_list=[eps],
output_dir=output_dir,
fontsize=15
)
fig.show()
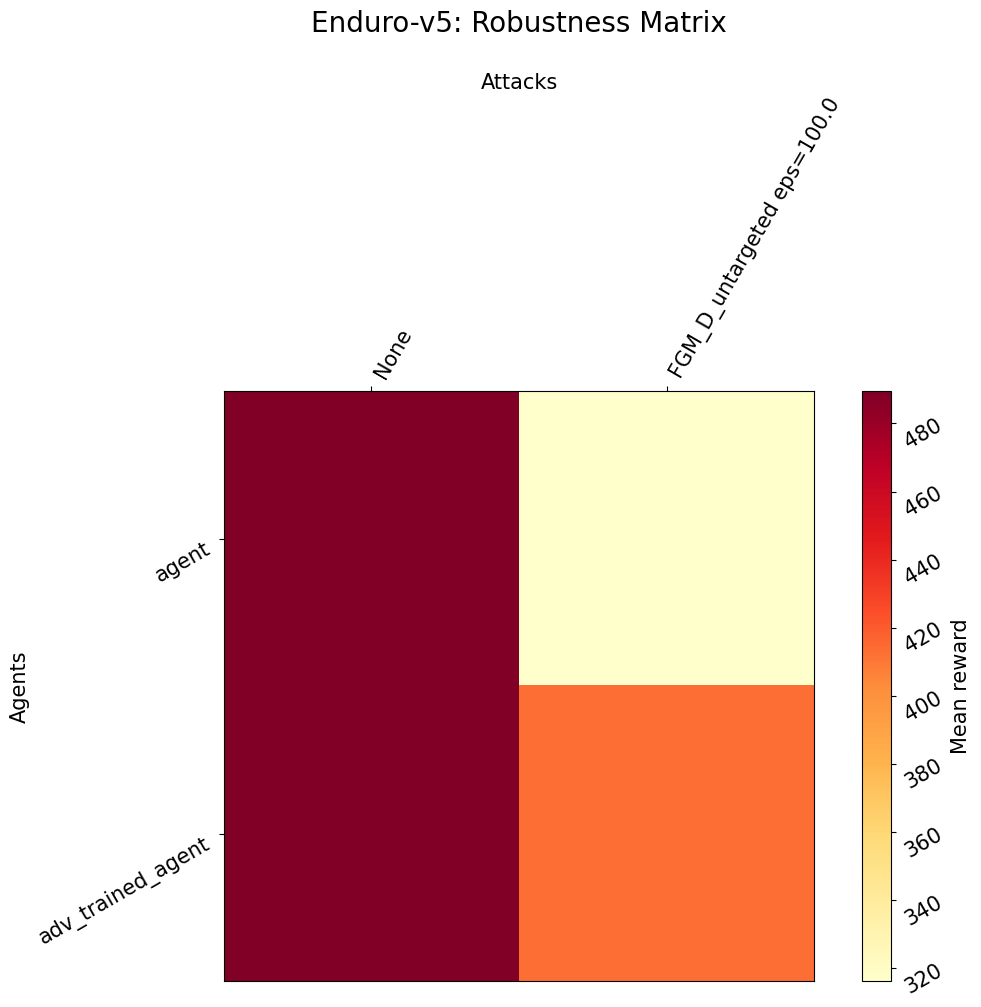
[ ]: